
|
Extracts length scale dependent dynamical information probed sample by computing the time autocorrelation function using a series of 2D area detector images in near real-time on a Hadoop HPC environment. It can be used to process data irrespective of the geometry of the measurement such as small angle in transmission, grazing incidence or under diffraction conditions. |
| Description |
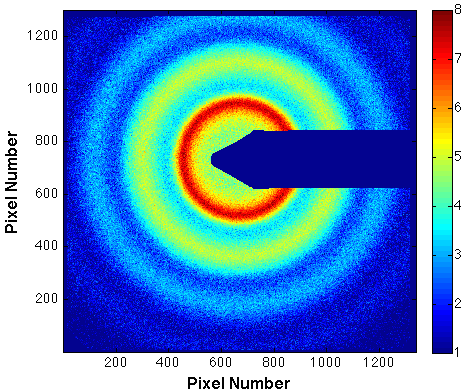
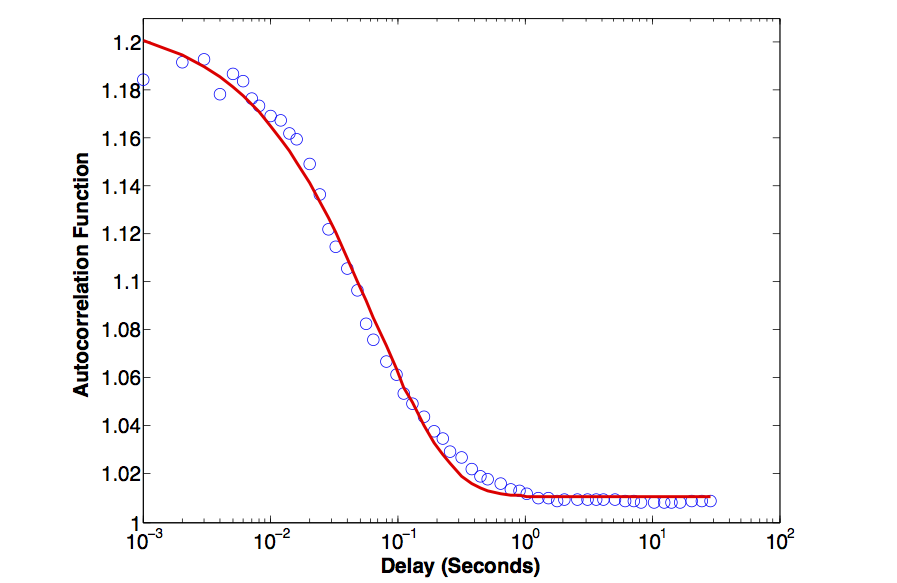
This XPCS technique deals with processing “Big Data” generated from high frame-rate area detectors operating at 100-1000 frames per second where each frame comprises typically of one million pixels. This can result in a sustained raw data throughput of 0.2-2 GB/s. Although the data is highly compressible using sophisticated compression algorithms where the throughput is typically reduced by 10x, there is still a very high and sustained data rate. A typical dataset comprises of 10K-100K frames resulting in files that are of tens of gigabytes in size. It is very important that the users can see the time autocorrelation functions in near real-time so they can make intelligent choices related to subsequent measurements on the sample. This software tool is developed in Java and uses the popular open source Hadoop MapReduce framework. MapReduce is a popular paradigm for problems that can be easily decomposed into independently computable chunks of data. The Hadoop framework parallelizes the data across a set of compute nodes on a distributed-memory cluster. In addition, a full analysis workflow pipeline has been developed around it, which provides a convenient user interface to launch and monitor jobs. The software is very efficient in terms of performance and while it is an offline analysis package, it can process data in near real-time, which enables users to readily view the correlation functions. This is combined with a MATLAB user interface that hides the complications of the low-level programming language from the general user. |
| Details |
|
| Virtualized Computing |
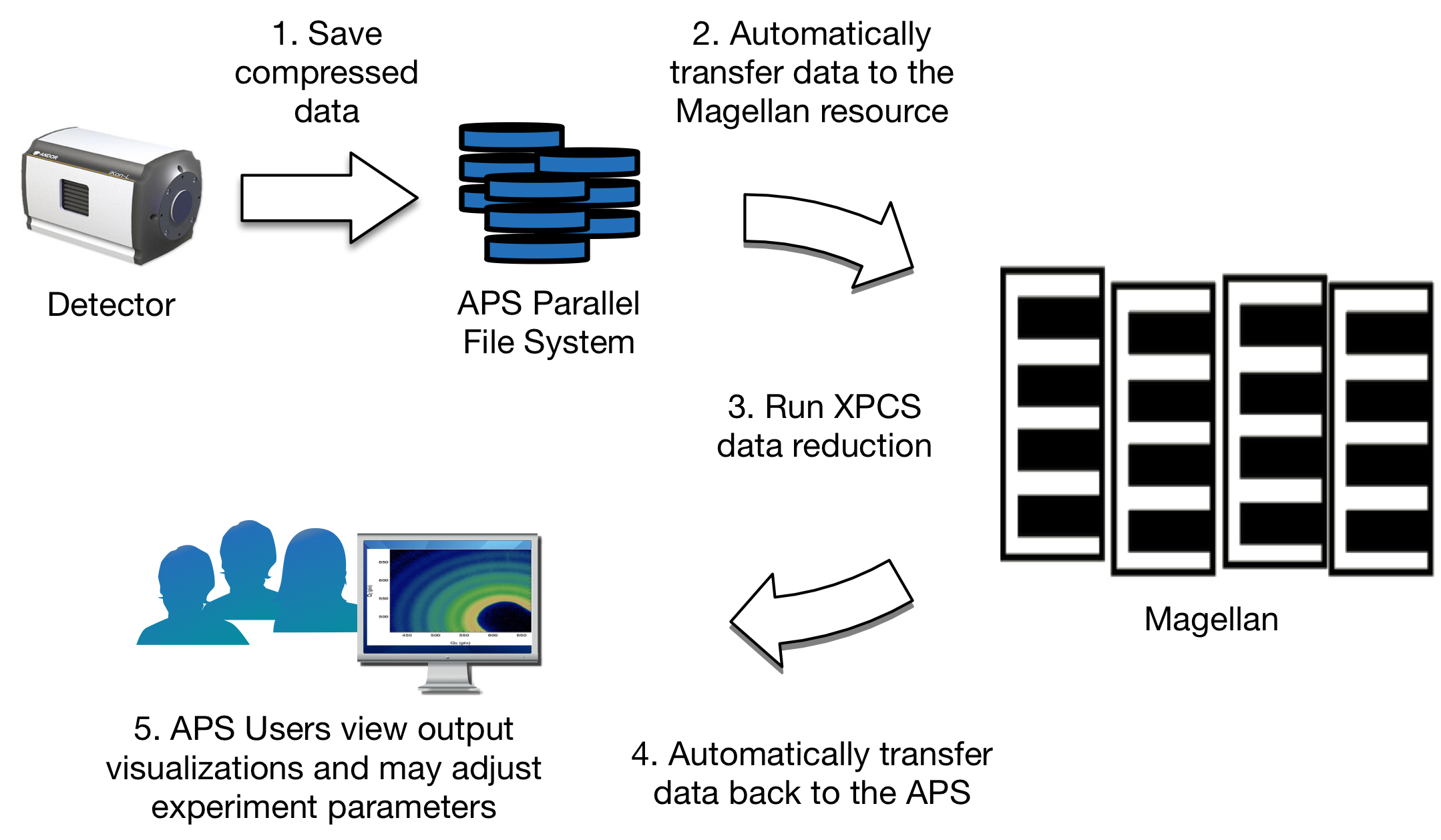
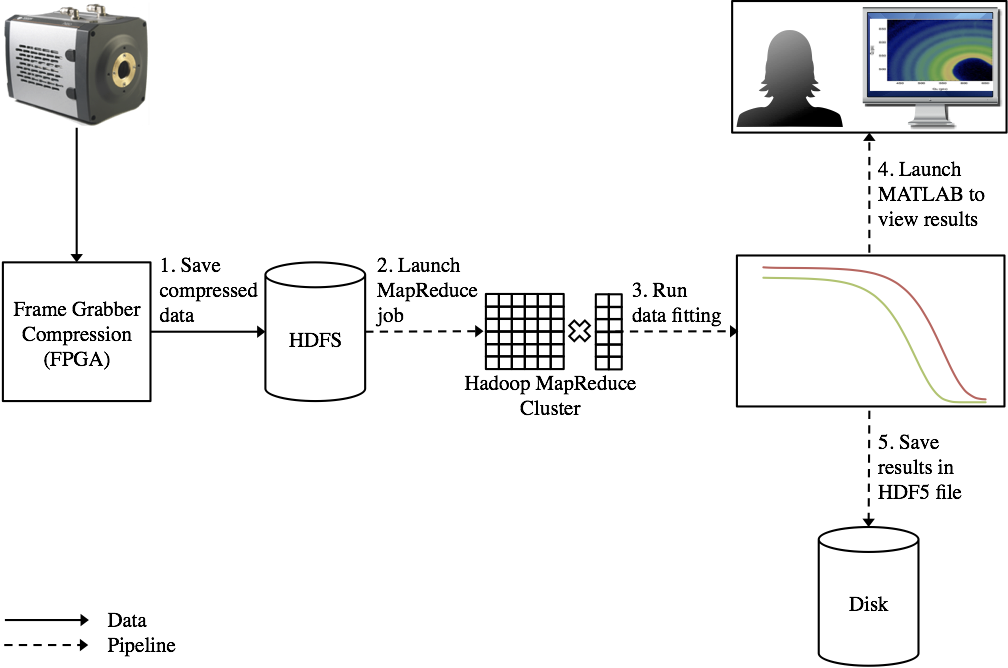
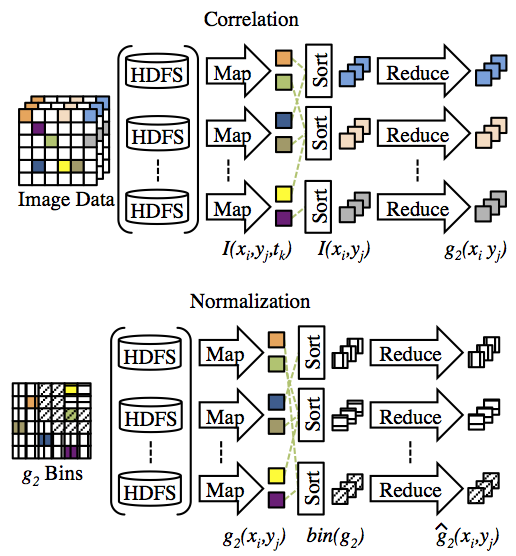
In order to realize this, the APS has teamed with the Computing, Environment, and Life Sciences (CELS) directorate to use Magellan, a virtualized computing resource located in the Theory and Computer Science (TCS) building. Virtual computing environments separate physical hardware resources from the software running on them, isolating an application from the physical platform. The use of this remote virtualized computing affords the APS many benefits. Magellan’s virtualized environment allows the APS to install, configure, and update its Hadoop-based XPCS reduction software easily and without interfering with other users on the system. Its scalability allows the APS to provision more computing resources when larger data sets are collected, and release those resources for others to use when not required. Further, the underlying hardware is supported and maintained by professional HPC engineers in CELS, relieving APS staff of this burden. The XPCS workflow starts with raw data (120 MB/s) streaming directly from the detector, through an on-the-fly firmware discriminator to a compressed file on the parallel file system located at the APS. Once the acquisition is complete, the data is automatically transferred as a structured HDF5 file using GridFTP to the Hadoop Distributed File System (HDFS) running on the Magellan resource in the TCS building. This transfer occurs over two dedicated 10 Gbps fiber optic links between the APS and the TCS building’s computer room. By bypassing intermediate firewalls, this dedicated connection provides a very low latency, high-performance data pipe between the two facilities. Immediately after the transfer, the Hadoop MapReduce-based multi-tau data reduction algorithm is run in parallel on the provisioned Magellan compute instances, followed by Python-based error-fitting code. Magellan resources provisioned for typical use by the XPCS application includes approximately 120 CPU cores, 500 GB of distributed RAM, and 20 TB of distributed disk storage. Provenance information and the resultant reduced data are added to the original HDF5 file, which is automatically transferred back to the APS. Finally, the workflow pipeline triggers software for visualizing the data. The whole process is completed shortly after data acquisition, typically in less than one minute - a significant improvement over previous setups. The faster turnaround time helps scientists make time-critical, near real-time adjustments to experiments, enabling greater scientific discovery. This virtualized system has been in production use at the APS 8-ID-I beamline during the 2015-3 run. It performs over 50 times faster than a serial implementation. |
| Distribution |
|
https://github.com/AdvancedPhotonSource/xpcs-hadoop "High-Performance XPCS Data Reduction Using Virtualized Computing Resources", Faisal Khan, Nicholas Schwarz, Suresh Narayanan, Alec Sandy, Collin Schmitz, Benjamin Pausma, Ryan Aydelott, Proceedings of New Opportunities for Better User Group Software (NOBUGS) 2016, 16 October 2016 - 19 October 2016. "High-Performance XPCS Data Reduction Using Argonne’s Virtualized Computing Resource", Nicholas Schwarz, Suresh Narayanan, Alec Sandy, Faisal Khan, Collin Schmitz, Benjamin Pausma, Ryan Aydelott, and Daniel Murphy-Olson, APS User News, January 2016 (/APS-Newsletter/01-2016/High-Performance-XPCS-Data-Reduction-using-Argonnes-Virtualized-Computing-Resource). F. Khan, Hammonds, J., Narayanan, S., Sandy, A., Schwarz, N., “Effective End-to-end Management of Data Acquisition and Analysis for X-ray Photon Correlation Spectroscopy,” Proceedings of ICALEPCS 2013 – the 14th International Conference on Accelerator and Large Experimental Physics Control Systems, San Francisco, California, 10/07/2013 – 10/11/2013. F. Khan, Schwarz, N., Hammonds, J., Saunders, C., Sandy, A., Narayanan, S., “Distributed X- ray Photon Correlation Spectroscopy Analysis using Hadoop,” NOBUGS 2012, the 9th NOBUGS Conference, Poster Session, Didcot, United Kingdom, 09/24/2012 – 09/26/2012. |
| Acknowledgements |
| The XPCS computing system was developed, and is supported and maintained by Faisal Khan the XSD Scientific Software Engineering & Data Management group (XSD-SDM) in collaboration with Suresh Narayanan (XSD-TRR) and Tim Madden (XSD-DET) with funding from U.S. Department of Energy (DOE) Office of Science under Contract No. DE-AC02-06CH11357. The Magellan virtualized cloud-computing resource is supported by the Computing, Environment, and Life Sciences (CELS) directorate with funding from the DOE Office of Science.
Argonne National Laboratory is supported by the Office of Science of the U.S. Department of Energy. The Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit science.energy.gov. |